
Random Forest is not a Calibrated Classifier
What does it mean to have a calibrated classifier? Why is that important?
Let’s try to answer that question with a minimal amount of code.
What is a calibrated classifier?
According to the scikit-learn documentation, a calibrated classifier is defined in the following way:
Well calibrated classifiers are probabilistic classifiers for which the output of the predict_proba method can be directly interpreted as a confidence level. For instance, a well calibrated (binary) classifier should classify the samples such that among the samples to which it gave a predict_proba value close to 0.8, approximately 80% actually belong to the positive class.
In plain English, if I am Snow White and I predict that each of the ten apples in my basket has an 80% chance of having been poisoned, then the Evil Queen should have poisoned eight out of ten of those apples.
Why does it matter?
It’s common to use the probabilities that come out of machine-learned classifiers to make business decisions. For example:
- After having trained a classification model to predict clothing sizes, we report to the customers on our website that there is a 80% chance they need a size 10 and a 20% chance they need a size 12.
- We train a classification model to predict which customer reviews on our products are actually spam messages. We automatically remove customer reviews with a predicted probability of being spam higher than 75%.
- We’re trying to target a “Get out the Vote” campaign towards people who are unlikely to vote. If their probability of voting in the next election is less than 20%, we send them a postcard encouraging them to register to vote and reminding them of their polling place.
But what if these probabilities are just… wrong?
Well, that’s not good. Customers will buy the wrong sizes and be unhappy with their purchases. Too much spam will slip through the review filters. The wrong people will get our “Get out the Vote” postcards.
The Random Forest Classifier
The calibration of your prediction probabilities varies depends on the classifier you pick. (Logistic regression, for example, does produce calibrated probabilities.)
Why am I picking on random forest in particular? The random forest is one of the most commonly deployed classification algorithms in data science, and rightly so. It’s robust, easy to use, and typically requires less feature engineering to get good results than other methods.
But! As implemented in the commonly used scikit-learn Python package, random forest is not a well-calibrated classifier. A naive implementation that simply uses the probabilities of the scikit random forest classifier is probably not doing what you want.
Show me
It takes surprisingly few lines of code to demonstrate this. The notebook with the full code is available here.
Create classification data
Let’s start by making some classification data using the handy scikit make_classification function.
X, y = make_classification(n_samples=30000, n_features=3, n_informative=3, n_redundant=0, random_state=0, shuffle=False)
Train both logistic and random forest classifiers
Split the data into train and test sets. (Not strictly necessary for this example, but good practice regardless.)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
Train a random forest classifier and get predictions for the test set.
clf_rf = RandomForestClassifier(max_depth=3, random_state=0, min_samples_leaf=3).fit(X_train, y_train)
predictions_rf = clf_rf.predict_proba(X_test)
Train a logistic classifier and get predictions for the test set.
clf_log = LogisticRegression(random_state=0).fit(X_train, y_train)
predictions_log = clf_log.predict_proba(X_test)
Bin the predictions and plot the two sets of predictions
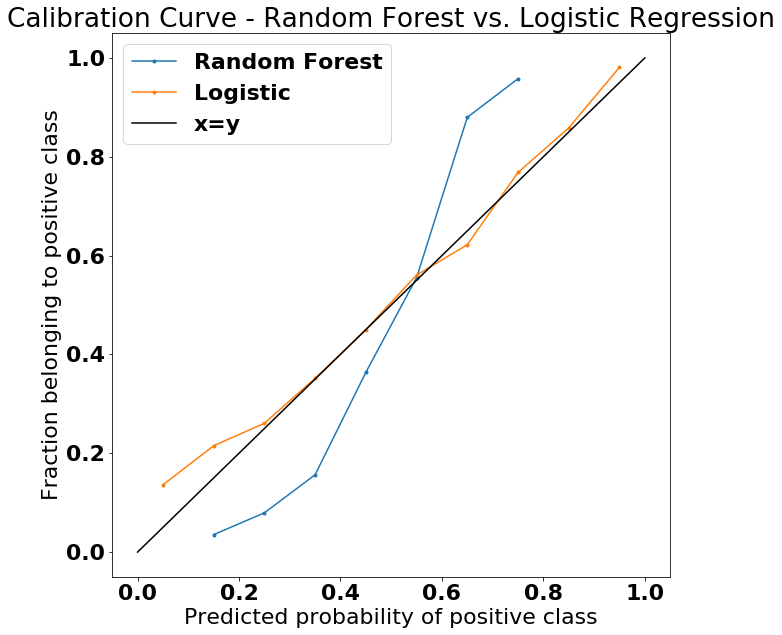
Bin the test data into ten bins based on the predicted probability of belonging to the positive class (y=1). If a classifier were perfectly calibrated, then the binned data would exactly follow the x=y line. That is, if we looked at all the data points that have a predicted probability of y=1 of 20%, then approximately 20% of those points would in fact have y=1.
We see that predictions coming out of the logistic regression are much closer to perfect calibration than the predictions from the random forest, which tends to overpredict on the low end and underpredict on the high end.
What would using the probabilities coming out of the random forest classifier mean in practice for our business decisions?
- For the customers that we believe have an ~70% chance of wearing a size 10, more than ~90% of them actually will. Because of the lower reported probability, some of them will get clothing of the wrong size and be unhappy with their purchases (or request costly refunds and exchanges).
- Of the customer reviews that the classifier scores as having a 65% probability of being spam (and therefore do not get filtered out of the data set), more than 80% of them will actually be spam.
- Our “Get out the Vote” campaign will miss a huge number of people. The group of people who are predicted to have a probability of voting of 40% (and thus would not receive a postcard) have an actual rate of voting of less than 20% (and should have received a postcard).
So what do we do? We can either pick a different classifier or figure out how to calibrate the output of an uncalibrated classifier. That’s too much to cram into one blog post, so I’ll tackle that in a follow-up.
Next time
Calibrating the output of your (uncalibrated) classifier.